Formal Semantics
Table of contents
One way to think about the world of languages (or the world in general) is in terms of formal systems. Attributed to David Hilbert and Gotlieb Frege, a formal system provides mechanisms for representing and reasoning a out systems. The term formal implies principled or formal in a mathematical sense.
Syntax
The syntax of a formal system defines the form of terms in that system. Syntax is frequently defined using a grammar as we used in the preceeding notes. We’re not going to do much with syntax, so little needs to be said other than providing a basic definition.
The alphabet of a grammar is a set of atomic symbols representing syntax elements that cannot be decomposed further. The rules of a grammar define legal orderings of symbols. The set of strings that are in the closure of the alphabet with respect to application of grammar rules is defined as the formal language described by the grammar.
As an example, consider the grammar of a subset of propositional logic:
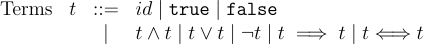
This format should be similar to the previous notes. The alphabet includes terminal symbols including true and false, but also symbols such as ∧, ∨, ¬. The id is a shorthand for all identifiers representing propositions. Grammar rules define ⇒, ⇔, ∧, and ∨ as binary operations and ¬ as a unary operator. The recursive nature of grammar rules over t allows arbitrary nesting of terms.
Inference Systems
Inference systems are defined by axioms and inference rules. They allow derivation of true statements form other true statements. You do this whenever you use mathematics to simplify a formula or solve equations for a quantity. We all know, for example, that 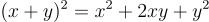 . We also know that is true in algebra regardless of what x and y represent. We could define this relationship using inference rules:
. We also know that is true in algebra regardless of what x and y represent. We could define this relationship using inference rules:

or an equivalence: 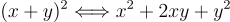
The classical notation for inference rules was defined in the previous chapter. The inference rule:
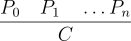
states that when P0 through Pn are true, then C is also true. The P’s are often referred to as premise or antecedents while C is the conclusion or consequent. The set of premise may be arbitrarily large, but there is only one conclusion associated with a rule. The special case when the set of premise is empty:
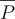
defines an axiom. Nothing need be true for A to be true, therefore it is always true.
As an example inference system we’ll look at propositional logic, the logic of true and false propositions that defines the heart of classical logic. We’ll start with one axiom that true is always true:
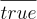
Nothing need be known to assert true is trivially true. It turns out that true doesn’t tell us much, but it does serve as a value in our logic. The other value is false. Consider what axioms or inference rules might have false as a consequent. Are there any?
Other inference rules define introduction and elimination rules for various operators. Introduction rules introduce their associated operation in an expression. The introduction rule for 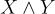 is:
is:
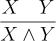
If X and Y are both known, then X ∧ Y is immediately true.
Elimination rules are the inverse of introduction rules. There are two for X ∧ Y:

Each rule allows one conjunct to be inferred from the conjunction. The first giving the left conjunct and the second the right. Note that introduction rules make larger terms from smaller term while elimination rules make smaller terms from larger terms. This will have important consequences when we talk about proofs.
Speaking of proofs, we now have a tiny subset of the inference rules defining propositional logic. How do we use them? Let’s do a quick derivation that combines inference rules. Specifically, let’s prove the commutative property of conjunction, 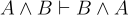 . We start by assuming
. We start by assuming 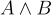 and using derivation rules to make inferences:
and using derivation rules to make inferences:
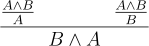
Note how the inference rules click together like Legos. Conclusion of rules plug into the premise of others. With a derivation from premise to conclusion we can say . The X ⊢ Y operator indicates there is a derivation from X to Y and we can skip the details in other derivations. If X is empty, we say that ⊢ Y is a theorem. Because it assumes nothing to start with, a theorem can be used anywhere.
We can add other inference rules for remaining logical operations. The elimination rule for ¬ is the double negative rule from classical logic:
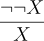
The introduction rule for ¬ is more interesting as a derivation is one of the premise. The premise of the elimination rule says that assuming X gives Y and ¬ Y is also known. This is a contradiction because X and ¬ X cannot be simultaneously true. Thus, X must be false:
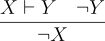
This is the classic proof by contradiction. It also suggests that if false is ever true, we have big problems because we can derive anything.
The rules for implication again perform eliminate and introduction of  . The elimination rule is known as modus ponens and says that if
. The elimination rule is known as modus ponens and says that if X and are known, then Y is also known:
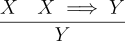
The introduction rule has a derivation in the premise. It says that if we can derived Y from X, then X implies Y or :
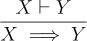
If assuming X allows us to derive Y, then we also know that .
Finally, we have introduction and elimination rules for logical equivalence.
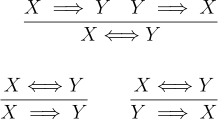
Using the implication introduction rule we can go a step farther and prove logical equivalence:
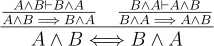
There is much more we can do with inference rules and systems, but this brief demonstration should give you an idea of how these things define formal reasoning processes. Just like Lego, simple things fit together in simple ways to develop complex and elegant systems.
Semantics
A language’s semantics gives its structures meaning. When we used inference rules to define how we reason about propositional logic, we provided a reasoning mechanism without regard to meaning. We could have changed the inference rules in a very simple way and gotten something that is not at all propositional logic. Let’s say we defined a completely wrong rule for implication like this:
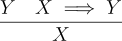
Clearly this is not how implication works, but it is a perfectly fine rule and we can reach conclusions from it. What makes it incorrect is the semantics of propositional logic. Semantics defines the meanings of language expressions using another mathematical system.
For propositional logic we can use the common notion of a truth table to define our operations:
| X | Y | X ∧ Y |
|---|---|---|
| F | F | F |
| F | T | F |
| T | F | F |
| T | T | T |
| X | Y | X ∨ Y |
|---|---|---|
| F | F | F |
| F | T | T |
| T | F | T |
| T | T | T |
| X | Y | X ⇒ Y |
|---|---|---|
| F | F | T |
| F | T | T |
| T | F | F |
| T | T | T |
| X | Y | X ⇔ Y |
|---|---|---|
| F | F | T |
| F | T | F |
| T | F | F |
| T | T | T |
| X | ¬ X |
|---|---|
| T | F |
| F | T |
We can’t easily derive new truths using simple truth tables, but we can with the inference system. To ensure the inference system only produces correct results we can compare it with what is specified in the truth tables. Let’s look at our broken rule for negation:
The rule says that if X and Y are both true, then X must also be true. Looking at the truth table for ⇒ clearly says otherwise. When Y is true and is true in the second row, X is false.
Discussion
Thinking of languages and mathematical systems as formal systems will serve you well. Throughout this class we will think of languages in terms of what they look like (syntax), how to manipulate them (inference system), and what they mean (semantics). At times the Hilbert system structure will be difficult to see, but it is always there.